陳洧農|特約記者報導
師範大學大眾傳播研究所於10月16日舉辦專題演講「AI偵測假新聞」,由王維菁所長主持,邀請到汪志堅教授主講,探討以AI技術來偵測新聞真假的可能性。講座內容分包含:AI的學習原理、AI偵測假新聞的研究成果、研究改進方向以及假新聞議題在查證之外的取徑思路。

主持人王維菁教授表示汪志堅教授進行的「AI偵測假新聞」研究剛好跟她所做的科技部前瞻式AI計畫類似。圖:陳洧農攝
汪志堅教授現任台北大學資訊管理所教授,兼任電子商務中心主任,研究方向為網路行為、網路心理學等。今年六月與世新大學廣電所教授陳才合著出版《假新聞:來源、樣態與因應策略》一書。
▍AI的學習原理
汪志堅表示,AI深度學習的原理跟人類很相似,比方說一個小孩從出生到會說話,可能要花一兩年,在這當中他不斷在聽、在累積資料、神經慢慢長出來,漸漸地他可以辨識特定的聲音所指涉的意涵。
汪志堅說,人工智慧的邏輯用簡單的方式講,就好比統計學的回歸分析,方程式一層一層的堆疊上去,「約三十年前開始想出這種想法時,叫它類神經網路,就是因為這樣的思維是從人的神經系統為藍本,就好比一個人要感覺到熱或是冷不是靠一個神經,而是身上非常多的神經綜合判斷出來。」
以人臉辨識技術為例,汪志堅指出,臉書蒐集了大量的人的照片,並且用AI把人名標註(hashtag)上去,如果標註錯誤,人們會把它取消,系統就會知道這是一個錯誤的標註,如果沒有被取消,則預設這是成功樣本。
由於臉書在全球擁有為數眾多的使用者,因此系統有極大量的練習機會。在早期,還只能從2、3人的合照中進行標註,現在已經能從有大量人數的團體照中標註出每個人。

汪志堅教授闡述AI偵測假新聞的可能與限制。圖:陳洧農攝
▍AI偵測假新聞 技術尚未成熟
汪志堅表示,在他與學生的研究中,使用了兩個資料庫:「Cofacts真的假的」與「新聞小幫手」,並使用了其中的80%來做訓練,20%進行測試。汪志堅說,以目前的研究結果而言,要以AI偵測新聞的真假是可能的,但還無法做到完全自動化,而且,不同性質的資料庫偵測效率不同。
在使用新聞小幫手的資料進行偵測時,準確率能達到88%,但在Cofacts資料庫中,有許多是來自Line的謠言,並不像新聞有撰寫的固定格式,變化性太大,因此只有67%的準確率。汪志堅表示,以AI偵測假新聞,雖然技術尚未成熟,但持續在發展中,方向上確實是可行的。
▍研究改進的方向
不平衡資料集:汪志堅表示,該研究最大的缺陷在於使用平衡資料集,也就是假設真假新聞各占一半,但在真實生活中幾乎不太可能有這樣的狀況,應嘗試使用不同的真假新聞比例,不應該是50%:50%。
更多資料:資料不足是另一個問題,由於AI深度學習的訓練需建立在大數據上,資料量若不足,正確率便無法提升。目前的假新聞資料集,將台灣事實查核中心、Cofacts、以及MyGoPen的資料加總後也僅有兩萬多筆,相較於Facebook幾百億筆的資料基礎,其訓練結果不可同日而語。
不同領域的假新聞:政治類、醫療保健類、財經類各類假新聞特性不同,須分別進行分析方可提升正確率。然而,以目前總數僅兩萬多筆的資料量,不足以對新聞進行分類。
語意、自然語言分析:應使用語意分析,自然語言分析,情感分析,進行預處理後,再開始進行深度學習。也就是將一篇文章真正的意思自動化地抽取出來,再尋找問題所在,才能避免「一整篇文章只錯了一個數字,卻造成極大傷害」的情況發生。
社會網絡分析:分析報導記者、媒體、其他媒體跟進報導、媒體聲譽等。換句話說,在分析時,報導是否具名、媒體是否具公信力、其他媒體是否也跟進報導等要素都必須納入考量。
其他深度學習:汪志堅教授表示, 今年開始流行一個研究方法,叫做BERT,結合了Attention、Transformer、ELMO,以及GPT的優點,並在許多學術研究中顯示出有助於效率的提升。
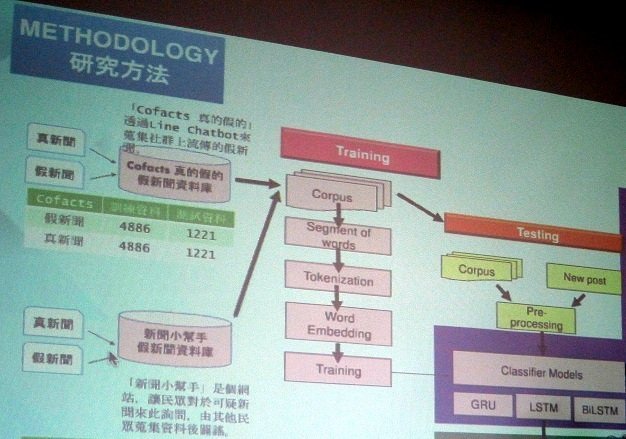
AI 深度學習的訓練方式,包括詞庫建立(Corpus)、斷字(Segment of words)、代碼化(Tokenization)、詞崁入(Word Embedding)等等。圖:陳洧農攝
▍AI偵測的限制
汪志堅表示,新聞往往都不會只有對於事件的客觀陳述,而是包含了後續發展的預測、對事件的評論、以及對事件細節的詮釋。由於每個人立場不同,對細節的評論也就大相逕庭。「我們都知道有言論自由,媒體當然也有言論自由,所以針對同樣事實同樣細節做的評論,只要它沒有過度扭曲,都會被認為是新聞自由。」
汪志堅指出,新聞的真假經常是程度上的問題,最嚴重的情況是子虛烏有,完全捏造,但記者如果真的寫下完全不存在的事,係屬非常罕見的情況,大多數狀況屬於對真實事件的細節做出誇大或扭曲。
汪志堅表示,在這樣的情況下,有個很重要的問題:有沒有「只錯一點點」的假新聞?
以蔡英文的「41歲退休」這則假新聞為例,汪志堅指出,該報導所有的推論與指控都源於一個錯誤:西元與民國年分的混淆。但是這樣的一個錯誤卻帶給當事人極大的傷害。
此外,假新聞有時是建立在遭竄改的圖像之上,比方民眾上街遊行時,所舉的標語遭修圖竄改為極端言論。若以圖像面積而言,遭修改的部分不到10%,但卻傳達出落差極為巨大的核心訊息。汪志堅表示,像這樣的假新聞,如果沒有人工過濾,AI要如何偵測,是很值得探討的問題。
▍新聞查證的困境:後真相時代
假新聞之所以成為一個非常棘手的問題,有部分原因是因為現今社會極化現象嚴重,人民的政治立場也越趨鮮明,而使得查證的結果難以取信於民眾。
「有沒有可能一個新聞被查證為假新聞之後,其他人都覺得你之所以說它是假的,是因為它不利於你?」汪志堅說,2016美國大選後有相關研究發現,親希拉蕊的網站所舉報的所有假新聞,都是跟希拉蕊有關;反之,親川普的網站舉報的都是跟川普有關的假新聞。「所以很多時候真假的問題,會轉變為立場的問題。」
▍假新聞,不是澄清就好:睡眠者效應
汪志堅以「碘酒讓傷口變黑」的網路謠言為例,說明有時即使假新聞被澄清,依然可能造成後續的影響。他說,即使衛生福利部澄清傷口留疤與碘酒無關,但時隔日久,人們記不清到底事實究竟為何,僅憑著依稀存留的印象,依然會在「寧可信其有」的心態下選擇不使用碘酒,這樣的現象稱之為睡眠者效應。
汪志堅教授表示,在當初「衛生棉長蟲吃掉子宮」的網路謠言出現後,他曾做過訪問調查,等事件過後三、四個月再問同一批受訪者是何品牌,受訪者寫下的幾乎都是錯誤的品牌。甚至,許多受訪者都表示不會再使用該品牌衛生棉。換句話說,該謠言即便在被澄清之後,依然使原先被攻擊的廠商退出市場,此外還連帶使其他廠商受到傷害。
▍假新聞議題的龐雜難解
汪志堅說,當他決定要出版《假新聞:來源、樣態與因應策略》這本書的時候,發現比想像中困難,而難處並不在於寫書,而在於出書。「因為每個人想像中的假新聞跟想處理的部分不一樣。有一些對假新聞非常專業的人,只關心如何把境外勢力趕出海外;另一些人想的是如何把假新聞標註出來。」
汪志堅表示,由於每個人對假新聞的問題意識都不同,因此當要彙整的時候,每個人都覺得那跟他想的不一樣,但是假新聞確實有許多不同的面向與切入點,值得我們去省思與探討。
關鍵字: AI, BERT, Cofacts, Line, MyGoPen, 人工智慧, 人臉辨識技術, 假訊息, 台灣事實查核中心, 回歸分析, 後真相時代, 新聞小幫手, 汪志堅, 深度學習, 王維菁, 睡眠者效應, 陳洧農, 類神經網路
《卓越新聞電子報》為讀者報導新聞媒體最前線,我們追蹤所有重大新聞演講活動現場、探索新聞媒體浮動的疆界!
- 假新聞是真的?人工智慧將火上加油!
- 「2019假新聞與事實查核工作坊」台中場 No.1/胡元輝|對抗AI新騙術 事實查核全球崛起
- 「2019假新聞與事實查核工作坊」台北場 No.1/GoogleXOpen Data|善用網路工具反制不實資訊
- 人工智慧在新聞編輯室的應用與道德風險
- 呂一銘|AI正在翻轉新聞媒體(上)
- 呂一銘|AI正在翻轉新聞媒體(下)
主編:鄭凱榕