在近年的幾次大選中民調頻頻失準,無法準確地預測選舉結果,也讓大眾意識到民調在預測選舉時似乎有其侷限之處。光以近兩年來看,美國參議院、英國大選、蘇格蘭獨立公投乃至希臘的紓困公投等幾項重要的投票,民調的表現都不盡理想。
探究民調可能預測失敗的原因,除了樣本可能有偏差外,民調無法準確預測會去投票的人,或是選民的偏好轉變,都會影響民調的可信度,本文也將針對民調機構「錯誤預估可能投票者」這個變項,做更詳盡的探討。
錯誤預估可能前往投票的選民,不一定是民調本身的抽樣偏差,而是民調公司在電訪時所受到的限制:難以確定受訪者有沒有說實話。根據民調公司的經驗,許多有投票資格的選民,未必會向電訪人員透露他所支持的候選人,也有些人在受訪時表示不願意投票,卻在大選之日前往投票。因此要如何準確預測可能投票的選民,往往成為各民調公司的首要任務。
研究如何進行?
此次研究以2014年的美國國會選舉為研究背景,透過大選前、後的電話民調,輔以全國的「選民資料庫」,來觀察透過預測可能前往投票的選民,能否使民調更準確。研究人員首先在2014年9月9日至10月3日這段期間,以隨機撥號(RDD, Random Digit Dial)電訪選民,詢問他們有關投票意願、對選舉活動的興趣、過去投票經驗與政黨偏好等等問題。
研究人員會在11月17日至12月15日期間再次訪問他們,調查他們在此次選舉中是否有投票、投給哪位候選人等,透過前後兩次的電訪,讓皮尤民調公司(Pew Research Center)或其他民調組織判斷何種選民前往投票的機率較高,進而提出可能選民的模型。
整項研究在選前與選後分別訪問了2424位美國選民,這些受訪者除了已經登記投票外,他們的資訊也可以在全國選民資料庫裡找到。全國選民資料庫是一份搜集了各選民的投票歷史與其他人口統計的資料表,各州政府或是各政黨都會搜集自己的選民資料庫,以利進行選舉的各項研究。
選民資料庫也是許多競選陣營常使用的民調方式,美國共和黨與民主黨都花費許多資源建立起自己的資料庫名單。這些政黨利用選民過去的投票歷史,來確保受訪者在過去都有投票行為,進而以此來預測未來的選舉。
電話民調則常用在許多民調公司或大型新聞機構的民調上,他們會以隨機撥號對美國人民進行隨機抽樣,再經由一系列問題如過去投票習慣或投票目的等,找到那些可能投票的選民。
這次針對2014美國國會大選的研究結合了兩者,除了在一開始使用RDD進行抽樣後,再搭配選民資料庫的資訊,讓訪問的內容與選民投票歷史都能放入分析中。這樣的分析模式,比起直接採信那些在電訪中表示「我有登記投票」、「我會去投票」等受訪內容,能使民調預估更加準確。
2014美國國會選舉分析
在上述分析為什麼選舉民調有時與大選結果不符的原因,「偏差的研究樣本」是其中一項因素。但在此研究中,民調顯示51%表示會投共和黨,45%表示會投民主黨,幾乎與選舉結果相同,表示就偏好而言,樣本在這次選舉中是沒有偏差的。
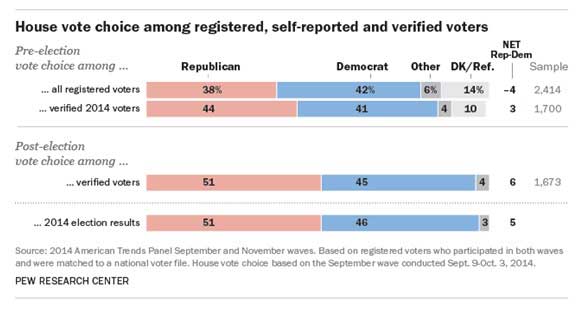
真正的原因在於第二項因素「預測會出席投票的人」,當選民在最後一刻改變投票意願時,民調便可能出現偏差。12月的選前民調數據顯示,登記選民當中有42%偏好投給民主黨眾議院參選人,38%的人想投給共和黨,民主黨在此民調中領先4%。但這個數據僅透過電話隨機撥號取得,沒有輔以資料庫來篩選可能投票的人。若加入「選民資料庫」協助預測,將「在大選之日可能出席投票」的因素一併考慮,我們就會發現共和黨其實領先了3個百分點 (44% vs. 41%),反轉先前的預測。
當然,要看哪一項民調比較準確,大選結果是最好的判斷依據,2014年國會的大選結果出爐,共和黨在此次眾議院的選舉贏得了過半的選票,領先民主黨近六個百分點(51.4% vs. 45.7%)。這些數據顯示,若單純只做電話民調,則失誤的機率是相對高的。但如果結合了選民資料庫,就可以透過每位受訪者的投票率,篩選可能投票的選民,得到更準確的投票預測。
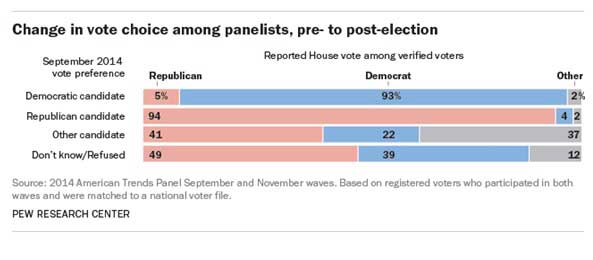
不過,最後共和黨以領先6%的差距勝選,先前預測的3%仍不夠準確。為什麼透過選民資料庫的協助,民調還是無法完全準確預測選舉?這與民調失準的第三項原因有關,也就是選民的偏好有所改變。透過選後訪問,研究發現選民支持的對象在電訪會與選舉當天有所不同,從此次美國國會選舉來看,有部分選民在受訪時尚未有明確政黨偏好,但在最後一刻將票投給共和黨,才會讓共和黨的得票率增加。
雖然這些在最後改變心意的受訪者,某種程度影響了選前預測及最後大選結果,但這樣的差異不至於影響民調預測的大方向,真正影響的主因仍在於支持者出席投票的機率。在共和黨的支持者中,73%的研究受訪者有去投票,但民主黨的支持者,雖在電訪中支持民主黨,卻只有61%真正有去投票。
預測「可能投票者」的模型
既然精準預測「可能投票者」成為民調準確與否的關鍵,如何能建立一個能夠預測的模型,也成為民調公司在民調時最大的挑戰。
蓋洛普民調公司(The Perry Gallup)曾建立了一系列的訪談問卷,作為理解選民偏好與投票意願的參考,這項問卷至今仍被許多民調公司沿用,不過各個民調會依據其他需求,加入關於黨派偏好或意識形態等等的問題。
蓋洛普可能選民指數(The Perry-Gallup likely voter index)則是一個透過該問卷來預測「可能投票者」的模型,它嘗試建立出一個量表,來區分每一位受訪者會前往投票的可能性。其測量的方式很簡單,在下方表中的七題問題中,若受訪者回答到特定的答案,就可以獲得一分。舉例來說,當受訪者被問到「您是否曾在您的選區投過票?」,而回答「是」時,就會得到一分。不過有些較年輕的受試者,因為過去沒有投票的經驗,會先給他們額外的一分,再做計算。
若受訪者回答「絕對不會去投票」或是根本沒登記投票的選民,會被直接視為零分。在一系列的問題後,每位受訪者會得到0至7分的分數,分數越高,表示去投票的可能性越大。

其他模型如機率模型(Probabilistic Model)也是以蓋洛普問卷為基礎,建立統計模型來計算每位受訪者可能投票的機率,也算出每項問題與最後投票結果的相關係數。這些預測可能投票者的模型,再加上選民在資料庫裡被記載的投票歷史,都能夠使民調的推算更加精準。
預測「可能投票者」成民調關鍵
整個研究顯示,只要能夠準確得知可能投票者,就可以得到較為準確的民調結果。加入選民資料庫分析後,得到共和黨贏三個百分比的民調結果,推翻之前的預測的不足(先前預測共和黨會落後4個百分點)。而之所以共和黨在最後會有6個百分比的領先,則是因為有些受訪者改變投票偏好。
不過目前研究仍有其困難之處,要如何將這些資料庫與隨機撥號的民調完整結合,仍是一項待解決的問題。要與選民資料庫結合,必須要有受訪者的姓名與地址,而許多選民並不願意在電訪中提供這類含有個人隱私的資料。
在過去的民調歷史上,並非每次選舉的民調都完全失真,過去幾次美國總統大選的全國民調,其實都能準確預測政黨分裂後的投票數,2012年以州為單位的民調也大致上能精準預測各州的投票結果。但是一到期間選舉,尤其是本研究所探討的2014年選舉,預測卻頻頻失準,才會讓人懷疑民調是否有辦法準確得知選民的政黨認同以及他們投票目的。
每一次的選舉都是完全不同的情境,都是一個可以單獨研究的個案。以這次研究來看,此研究著重在2014年美國期中選舉,但這次的選舉投票率超乎預期的低。因此這些分析選民的模型在日後的選舉中,仍需要被拿來一次次驗證,運用在其他選舉案例上,才能夠確定這些模式是否能通用於每一次的選舉。